Introduction
The primary goal behind this project is to develop a distributed and highly scalable stateless email validation SaaS based api system that validate any given email of known origins under 500 ms to identify if the email is safe for the system and deliverable without sending an actual email and prevent spams and bounce.
Advantages
Helps prevents fraudulent users on the system.
Helps prevents spam and free trial mis-use.
Helps on blocking temporary emails in the system.
Helps on reducing the number of email bounce.
Helps on preserving the email server reputation with bounce prevention.
Requirements and Goals
Validate any email of known origin under 500 ms.
Highly scalable and deployed to the global edge networks.
Credit based system.
Project level limits and metrics.
Fully documented and easy to use REST API.
Native SDKs for popular Programming Frameworks.
CLI application for higher flexibility.
Bulk Validation.
Checks and Validations
Valid format of email
No catch all domain
Domain registration and DNS MX records
Email is deliverable
Email is not generic email
Temporary email check
Blacklist check
What does known origin means?
Known origins means the domains or hostnames that the system has already seen in the past and has already collected the data for it keeping it updated with current records and status.
For example, Let’s say our system hasn’t seen email address with domain example.com till now, then for the first time, it has to verify the checks like domain verification, DNS records, Blacklist checks and more. This takes time and depends upon the external sources and factors. So for first unknown origin email, it will take some time. May be up to 2 seconds. But after the processing has been done for the initial email, now all those results are cached and stored in the system. So the domain now becomes known origin.
And for the newer emails of the same origin, system only has to perform certain subsets of check. And other general informations will be rechecked and renewed by the system automatically in the background to keep the information up to date.
Architecture
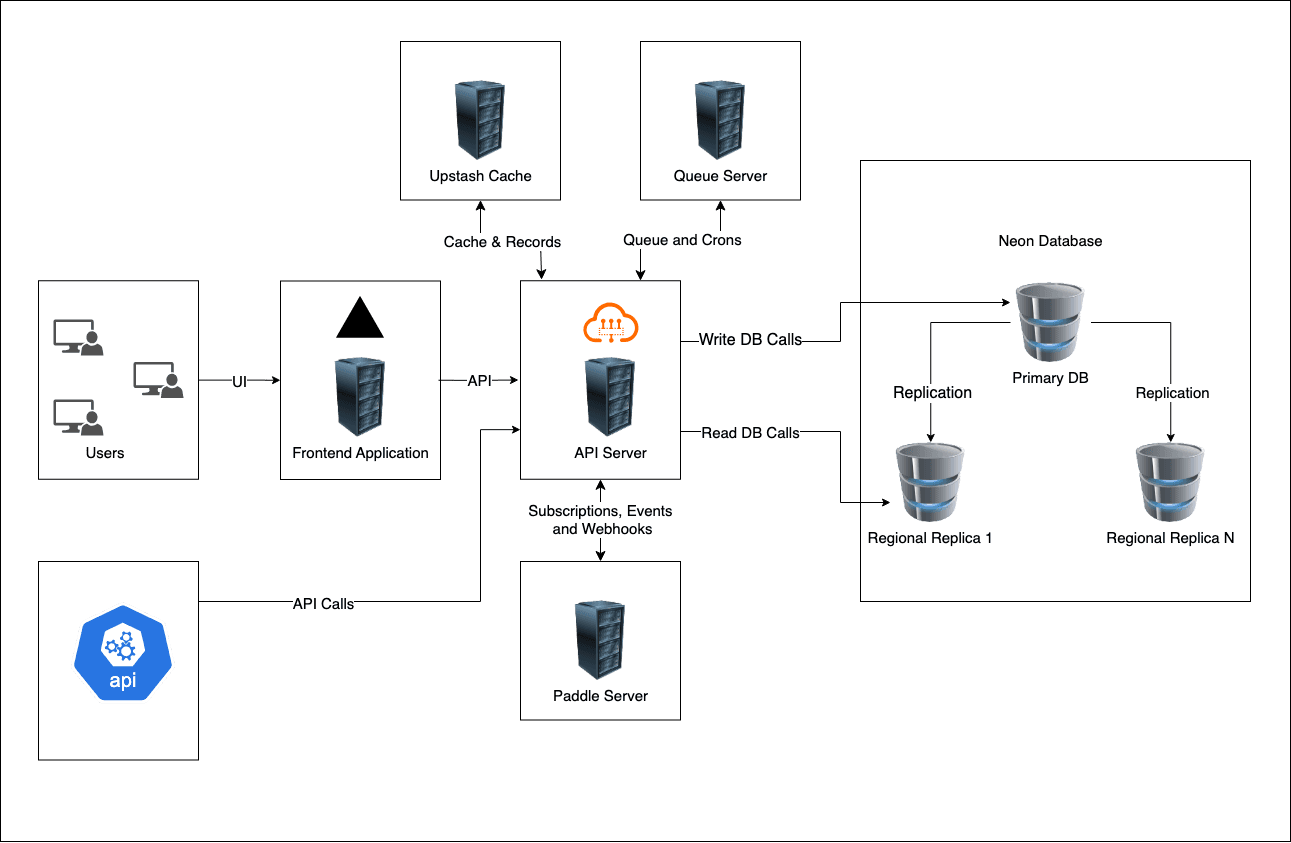
Above diagram represents and maps the architecture of our system using high level components.
API Server
This node server as a primary backend api server handles all the authentication and authorization, core business logic, primary email validation and cordinates between all other components and third party services.Neon Database Cluster
This node is a database cluster with replication and high availability with multiple read replicas builtin and can be scaled according to the traffic and system load. There will be one primary write replica and multiple read replicas. All write operations will be directed to the primary replica for data consistency and prevent excessive race conditions. All other regional read replicas will replicate themselves and keep their data up-to-date with primary replica for lower latency for regional users.Frontend Application
This server hosts the UI interface for the system. All admin portals and user portals will be handled by this node.Upstash Cache
This node is responsible for storing the frequently accessed data as cache on regional read replicas for lower latency to regional users.Queue Server
This node is responsible for processing background jobs and cron jobs to handle operations like database cleanup, Regular DNS lookups for highly accessed domains, notification and emails processing, etc. This will work independently of the primary API server.Paddle Server
This node is a external thirdparty node and will be managed by the Paddle themselves. Our API server will communicate with the node when needed for the subscription, payments and billing related operations. Subscribing to plans, renew, upgrade, downgrade, cancellation, automatic payment processing, payment methods, etc will be handled by the Paddle Server.
Phase 1 : Instant Validation
Estimation: (0 - 50 ms)
Criteria: If any blocking check fails, returns immediately with error details. Otherwise proceed to Phase 2.
1. Format Validation
Behaviour : Synchronous, Blocking
Result : PASS/FAIL
Details:
Regex validation against RFC 5322 standard
Check for basic structure:
local@domainValidate local part length (max 64 chars)
Validate domain part length (max 255 chars)
Check for invalid characters

2. Temporary Email Check
Behaviour : Synchronous, Blocking
Result : PASS/FAIL
Details:
Query cached temporary email domains

3. Blacklist Email Check
Behaviour : Synchronous, Blocking
Result : PASS/FAIL
Details:
Query cached blacklisted email and domain list

4. Generic Email Pattern Check
Behaviour : Synchronous, Non-Blocking
Result : PASS/WARN
Details:
Maintain a in-memory list of generic email patterns.
Check against the list

Phase 2 : Domain & DNS Validation
Estimation: (50-200ms)
Execution: Parallel execution of all domain-related checks
Phase 2 Exit Criteria: If domain doesn't exist or has no MX records, return failure. Otherwise, proceed to Phase 3 (conditionally).
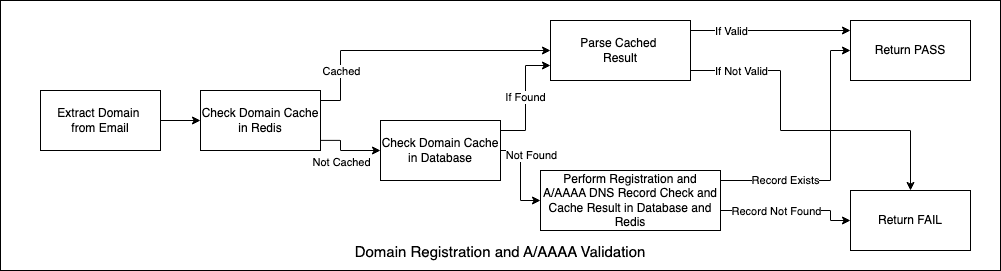
1. Domain Registration & DNS Check
Behaviour : Asynchronous, Blocking
Result : PASS/FAIL
Details :
First check on the redis cache and decide based on the result.
If the domain is not in the cache, check domain registration in database.
If not exists, perform a domain registration check and DNS record checks.
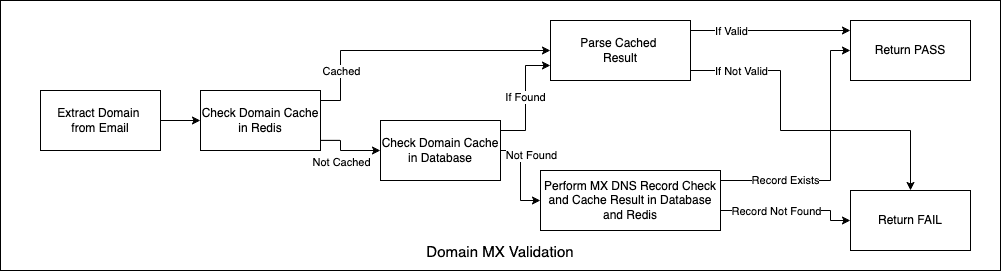
2. MX Record Validation& DNS Check
Behaviour : Asynchronous, Blocking
Result : PASS/FAIL
Details :
First check on the redis cache and decide based on the result.
If the domain is not in the cache, check domain MX status in database.
If not exists, perform a MX record checks.
Store the result in the database and redis cache.
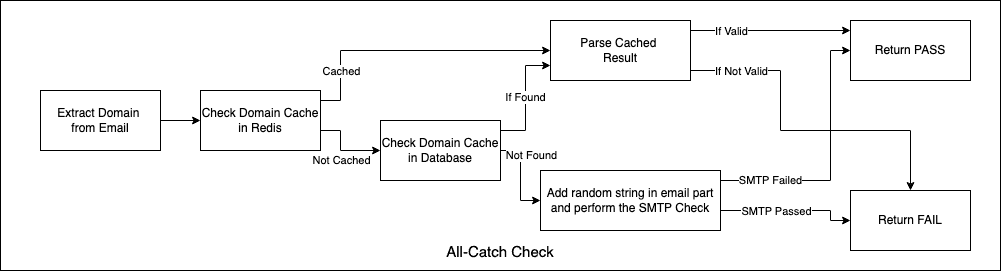
3. Catch - All Domain
Behaviour : Asynchronous, Non-Blocking
Result : PASS/WARN/UNKNOWN
Details :
Query catch-all domain table
Table maintained by Cron Job
If domain is not in cache/database
Default is unknown
Queue for background verification
Allow verification to continue
Phase 3 : SMTP Deliverability Verification
Estimation: (200-500ms)
Execution: Only runs under specific conditions
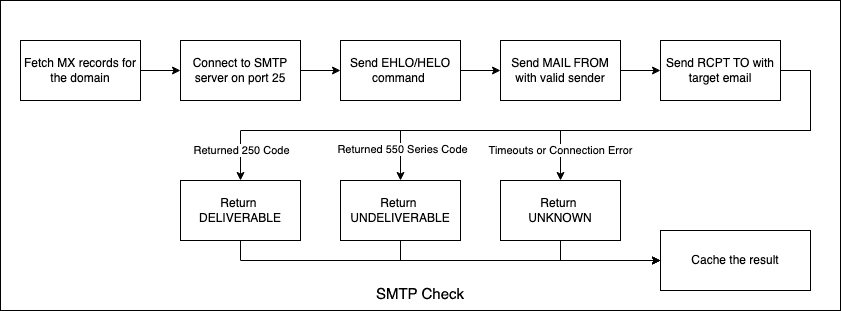
1. SMTP Verification
Behaviour : Asynchronous, Blocking for individual , Non-Blocking for bulk
Result : DELIVERABLE/UNDELIVERABLE/UNKNOWN
Details :
Connect to SMTP server on port 25 (timeout: 200 ms)
Send EHLO/HELO command
Send MAIL FROM with valid sender
Send RCPT TO with target email
Check response code:
250: Email exists and deliverable
550/551/553: Email doesn't exist
450/451/452: Temporary error (retry)
Other: Server error
Send QUIT and close connection
Result Processing:
If any server returns 250: Email is deliverable
If all servers return 550-series: Email doesn't exist
If timeout or connection error: Mark as "verification_failed"
Cache result with appropriate TTL
Tech Stack of Choice
NextJS
Excellent for TS based frontend application using React.
Tailwind and Shadcn
Excellent extensible and accessible prebuilt Opensource UI components based on Radix UI and Tailwind with excellent additional community components and support.Neon Database (Postgres)
Distributed Postgres database system on the edge with global presence and Point-In-Time Recovery and excellent HTTP based api support with no connection pool limit best suitable for distributed serverless architecture.Upstash Redis
Highly available, low latency worldwide, infinitely scalable Redis-compatible database with automatic backups, durable storage and multi region replication.Drizzle ORM
Efficient and Type Safe Database schemas and operations.Hono for API
Efficient and Lightweight framework with native support on Cloudflare Workers and can be deployed on the edge runtimes.Subscription with Paddle
Simplified and easy to understand subscription system. A good alternative is Stripe with excellent documentation and development guides.Queue Server with Bull
Server-full express server instance with bull queue server for crons, queues and notifications.Why server-full queue server you might ask?
Bull queue server requires a persistent redis connection to function properly. But Serverless architecture does not support persistant TCP connection which redis is based on. So, we will need a server-full architecture based frameworks or runtime.How does they communicate with the master server?
Once the server initializes with their role, they will make communicate with the master server through API to get the jobs and process them and submit the result.
Database Design and Schema
Product
Product defines multiple flexible plans with different limits and create a price hierarchy in the system.
Subscription
Subscription links organization with the corresponding subscribed plans and handles regular payments.
User
User is the primary entity of the system. Customer starts by creating a User in the system using the signup mechanism.
Organization
Organization is abstraction that allows multiple users/members to be part of same group and interact with common projects.
Project
Project allows user to create a separation of concern and allows users to use make multiple access controlled environments inside the same organization.
Member
Member allows multiple users to interact with common organization with granular level of controls, invitation and removals with multiple level of access.
Invitation
Invitation tracks the pending invitation of user on organizations with invitation expiration and acceptance tracking.
Apikey
Blacklist
Domain
Check
CreditHistory
OrganizationLog
UserLog
Background Jobs
To meet the goal of under 500ms, not all operations and checks can be done after the request has been received. Few data has to be refreshed and kept up-to-date in cache. Thats where the background jobs comes in. They keeps running on background and processes those data.
Job 1 : Blacklist Sync
Fetch from third party blacklist APIs
Merge with existing blacklist database
Update the Redis Cache
Remove expired entires

Job 2 : Temporary Email Provider
Fetch from third-party disposable email lists
Merge with existing temporary domains database
Update the Redis Cache

Job 3 : Domain DNS Refresh
Revalidate A/AAAA and MX Records
Update the Database and Cache

Job 4 : Domain Registration Refresh
Recheck domain registration after the domain expiry date has been passed
Update the Database and Cache

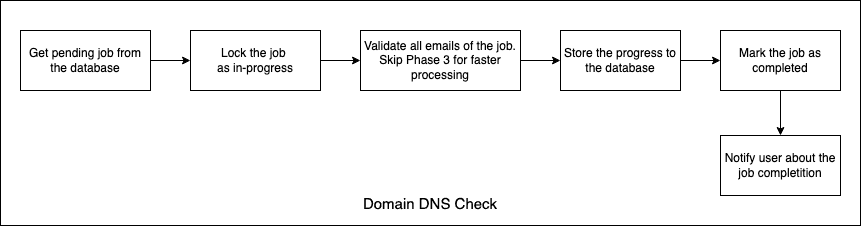
Job 5 : Batch Validation Processing
Process bulk validation requests asynchronously
Lock the job so other workers doesn’t get it
Redis Cache Keys
Keys | Type | Description | TTL |
|---|---|---|---|
email:validation:{email_hash} | Object | Stores information of email validation | 7d |
domain:mx:{domain} | Array | Stores array of mx records for a domain | 12h |
domain:valid:{domain} | Boolean | Stores whether the domain is valid or not | 7d |
domain:catchall:{domain} | Boolean | Stores whether the domain is catch all or not | 7d |
blacklist:domain:{domain} | Boolean | Stores whether the domain is on blacklist or not | 7d |
temp:domain:{domain} | Boolean | Stores whether the domain is on temp domain list or not | 7d |
Feasibility & Conclusion
Feasibility
Is this goal possible? Short answer is yes.
But, we have to take some factors into consideration.
We must have API servers on almost every continent and even multiple servers on multiple geographic locations of the same continent to cover the large area.
Each location should chosen equally distant apart from each other for equal global coverage.
Traffic for the API should be routed through Anycast IP address for better latency and failover redirect.
Database, Caching and API nodes of same region should be geographically near to each other as much as possible to reduce latency between them.
Long running jobs and tasks should be handled by the queue asynchronously instead of in the main thread which prevents main thread being blocked and unable to handle next traffic until the task completes.
Account level rate-limit should be kept in place to prevent spam.
Dynamic scaling should be configured which would scale up and down based on the realtime traffic.
Traffic behaviour and usage patterns should be tracked on every geographical locations and API should be move to the closer locations of the user base for lower latency to users.
DDoS Mitigation Strategy should be placed in place to prevent unauth api spam. When a bad actor hits the validation endpoint with invalid api token, our server will still have to process to find out that the api key is invalid, which will consume resources. If such requests are in millions, then our server will still take the hit.
Database and cache size will increase overtime. Proper backup and recovery mechanism should be kept in place with proper training to sys admins with regular simulated drills.